Hot Chips 2025:AIブームに向けた液体冷却技術の革新
2025-09-05

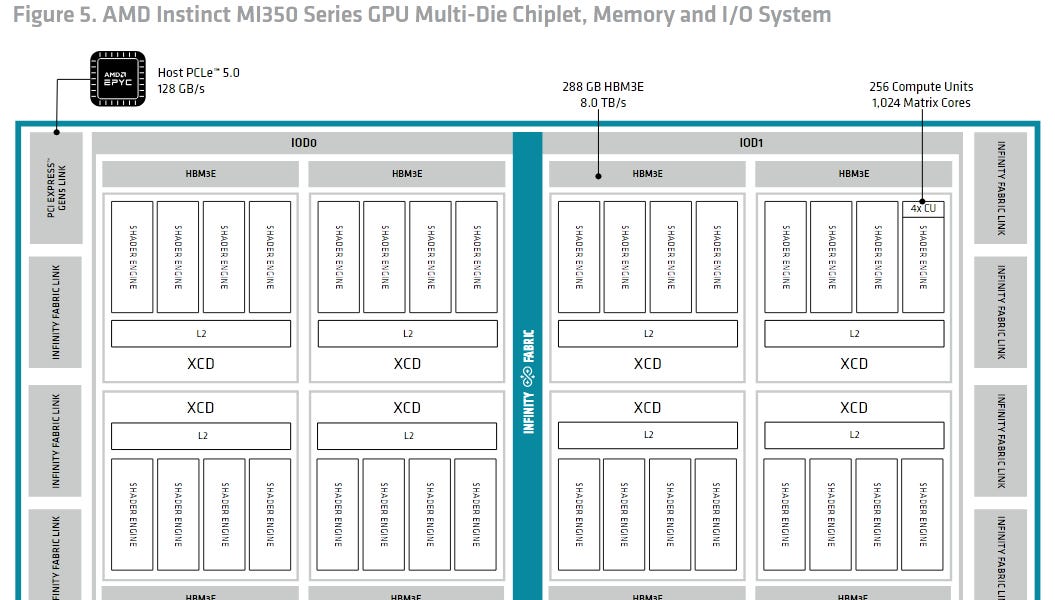
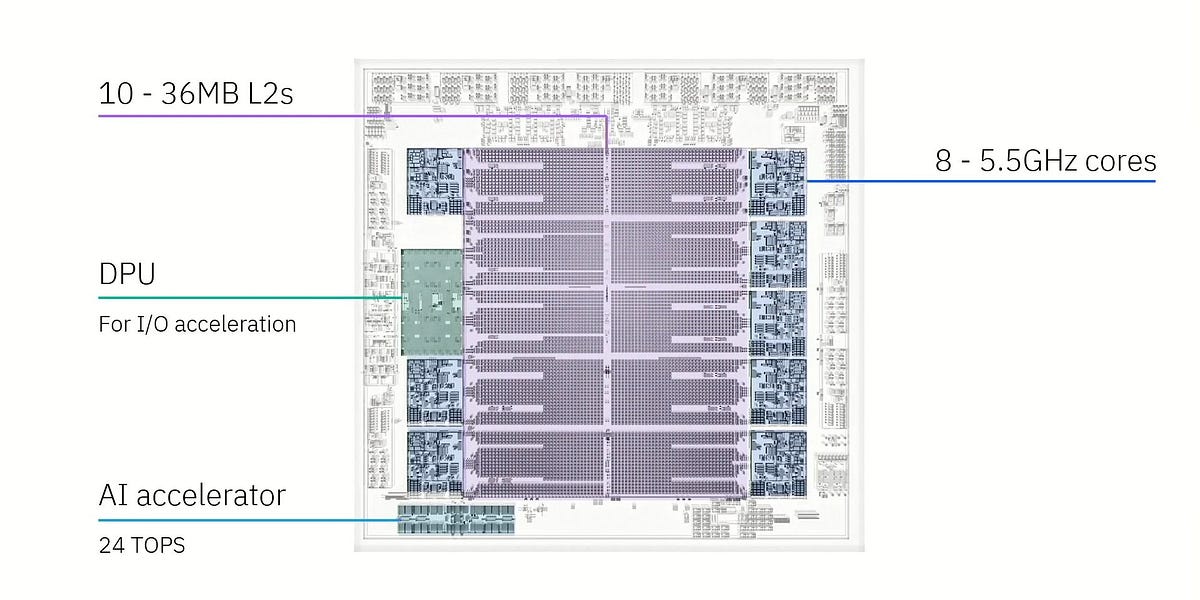
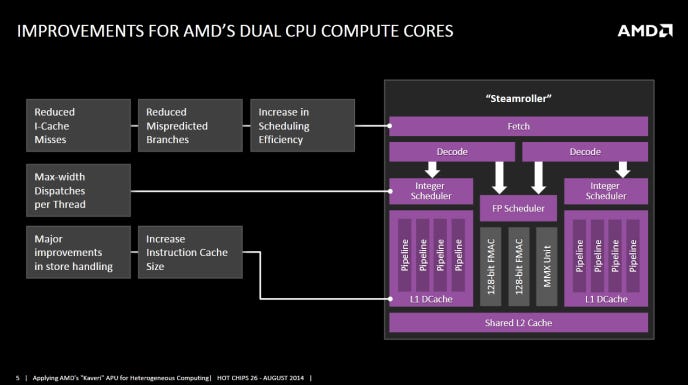
Hot Chips 2025では、AIチップ向けに設計された高度な液体冷却技術が展示されました。様々なメーカーが、チップのホットスポットを正確に冷却できる、マイクロジェットベースの冷プレートを発表しました。中には、ダイに直接水を噴射する技術も含まれていました。現在、サーバーアプリケーションに焦点を当てていますが、正確な温度制御は、将来、コンシューマーハードウェアにもメリットをもたらす可能性があります。また、軽量なアルミニウムや高効率な銅など、様々な素材の冷プレートも展示され、サーバーの重量や冷却ニーズに対応していました。AIチップの電力消費と発熱量の増加に対処するため、これらの液体冷却技術の革新は、データセンター冷却の重要なソリューションとなっています。
続きを読む
ハードウェア