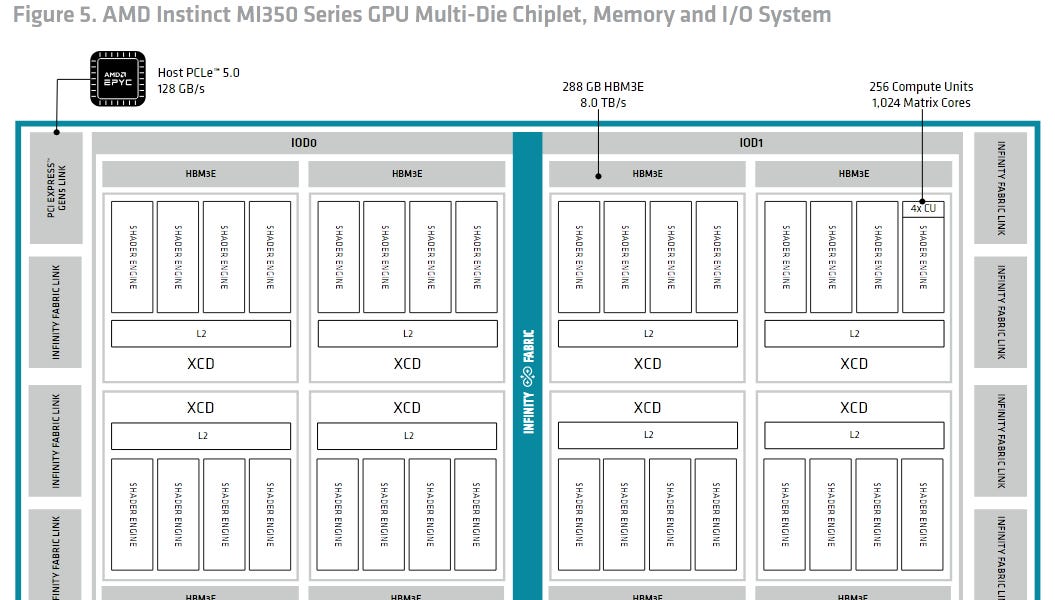
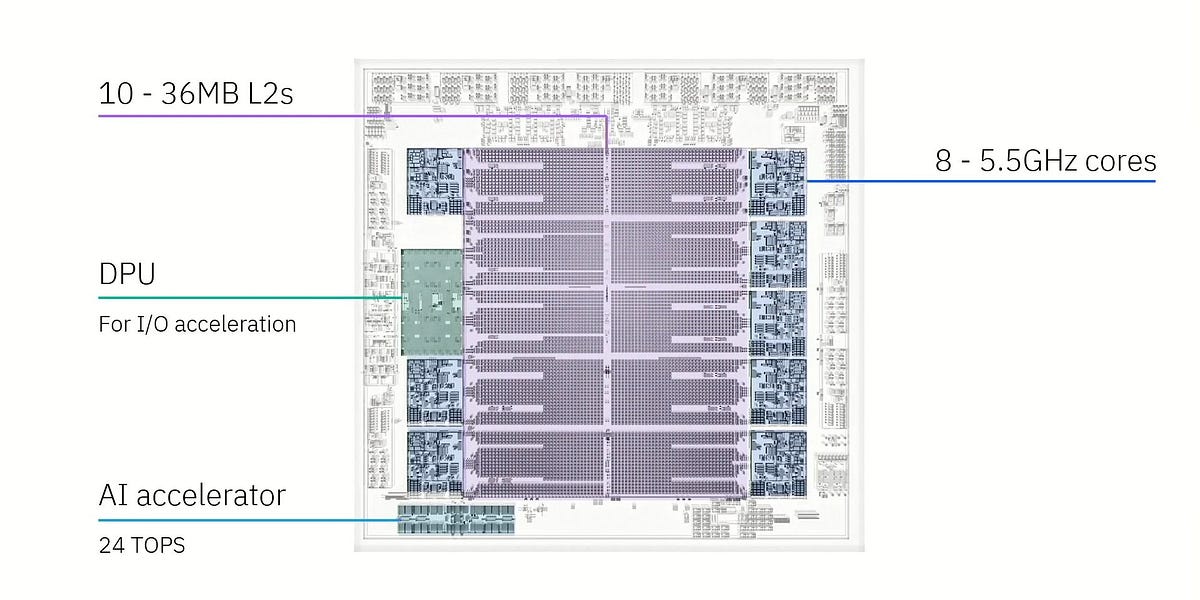
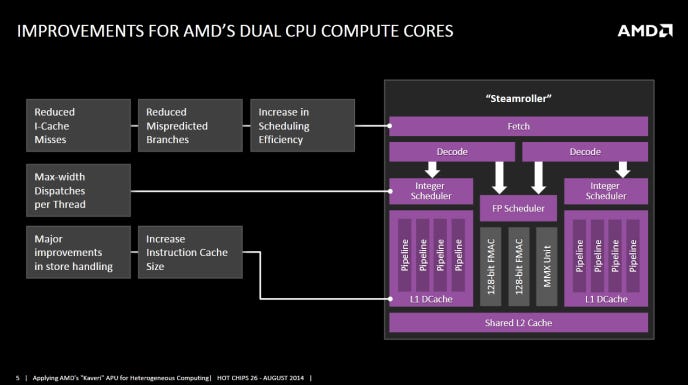
Hot Chips 2025: AI 붐을 위한 액체 냉각 기술 혁신
2025-09-05

Hot Chips 2025에서는 AI 칩을 위해 설계된 첨단 액체 냉각 기술이 전시되었습니다. 여러 제조업체가 칩의 과열 지점을 정확하게 냉각할 수 있는 마이크로 제트 기반 냉각판을 선보였습니다. 심지어 다이에 직접 물을 분사하는 기술도 포함되어 있었습니다. 현재는 서버 애플리케이션에 초점을 맞추고 있지만, 정확한 온도 제어는 미래에 소비자 하드웨어에도 이점을 제공할 가능성이 있습니다. 또한, 경량 알루미늄과 고효율 구리 등 다양한 재질의 냉각판도 전시되어 서버의 무게와 냉각 요구 사항을 충족했습니다. AI 칩의 전력 소비량과 발열량이 증가함에 따라 이러한 액체 냉각 기술의 혁신은 데이터 센터 냉각의 중요한 솔루션이 되고 있습니다.
더 보기
하드웨어