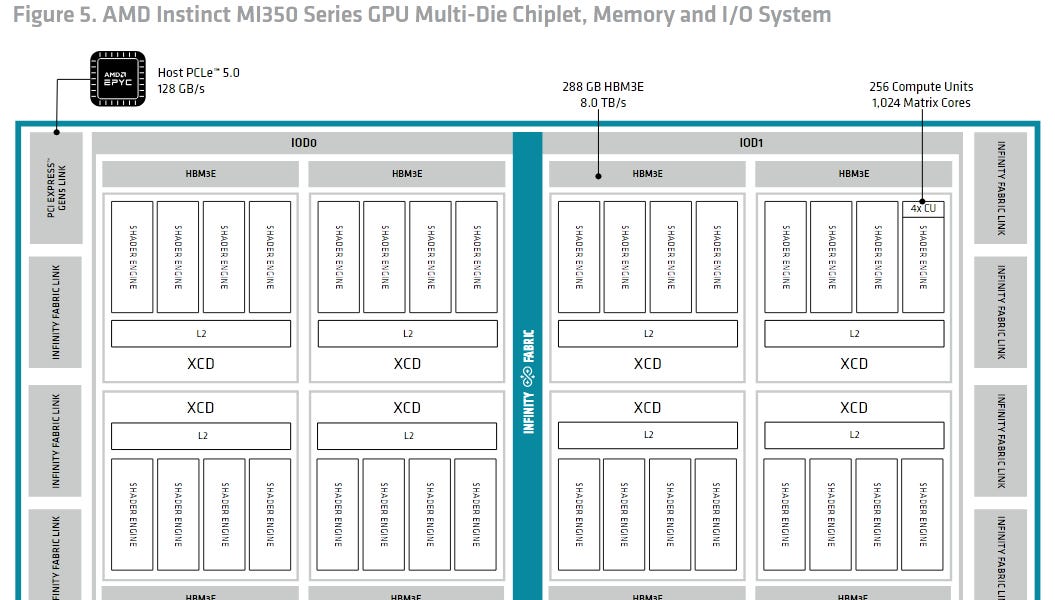
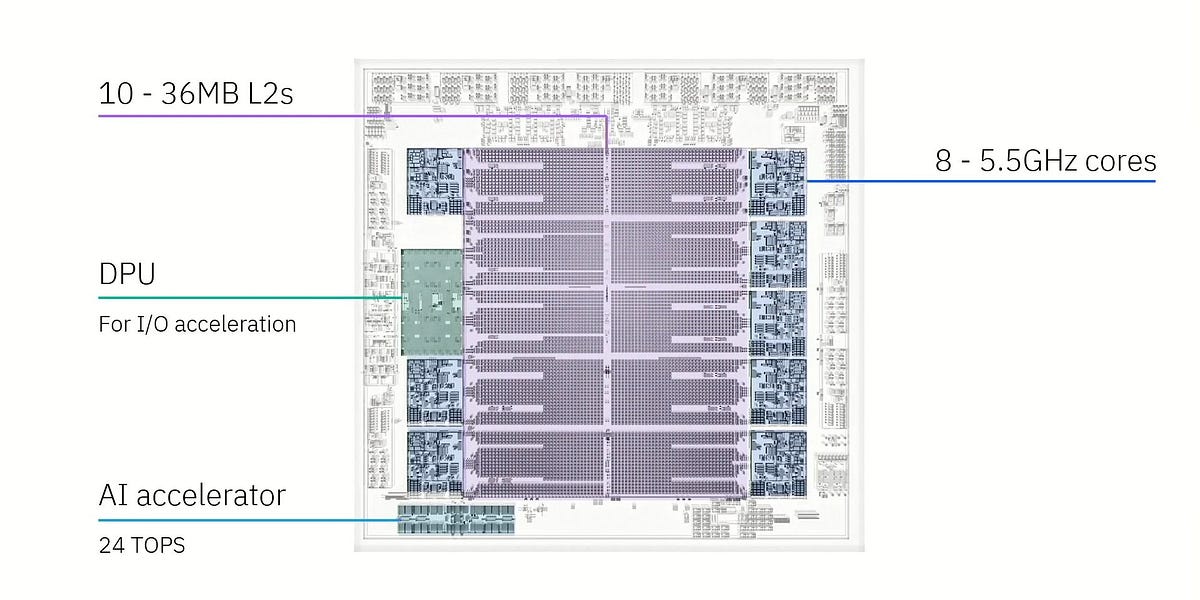
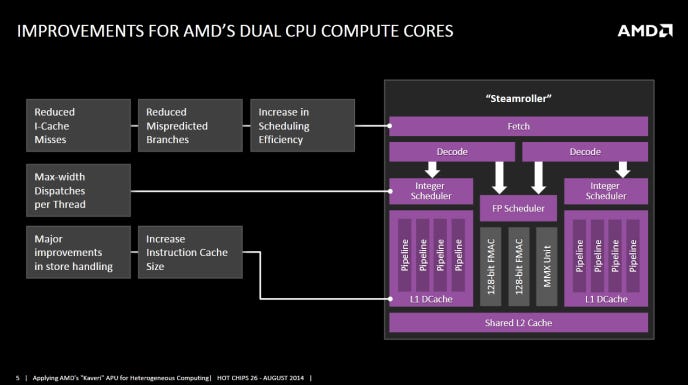
Hot Chips 2025 : Innovations de refroidissement liquide pour le boom de l'IA

Hot Chips 2025 a présenté des technologies avancées de refroidissement liquide conçues pour les puces d'IA. Les fournisseurs ont exposé diverses plaques froides à micro-jets capables de refroidir précisément les points chauds des puces, voire d'injecter directement de l'eau sur le die. Bien qu'actuellement axé sur les applications serveur, le contrôle précis de la température offre des avantages potentiels pour le matériel grand public à l'avenir. L'exposition présentait également des plaques froides en différents matériaux, tels que l'aluminium léger et le cuivre hautement efficace, répondant aux différents besoins de poids et de refroidissement des serveurs. Face à l'augmentation constante de la consommation d'énergie et de la dissipation thermique des puces d'IA, ces innovations en matière de refroidissement liquide deviennent des solutions cruciales pour le refroidissement des centres de données.
Lire plus