从零构建大型语言模型:向量、矩阵与高维空间
2025-09-06

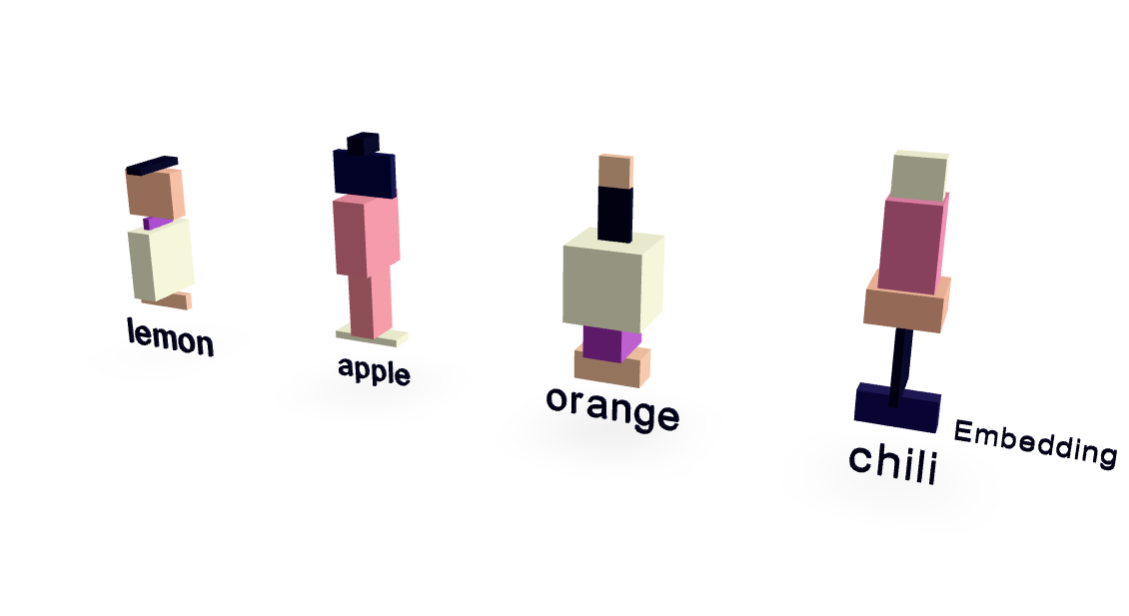
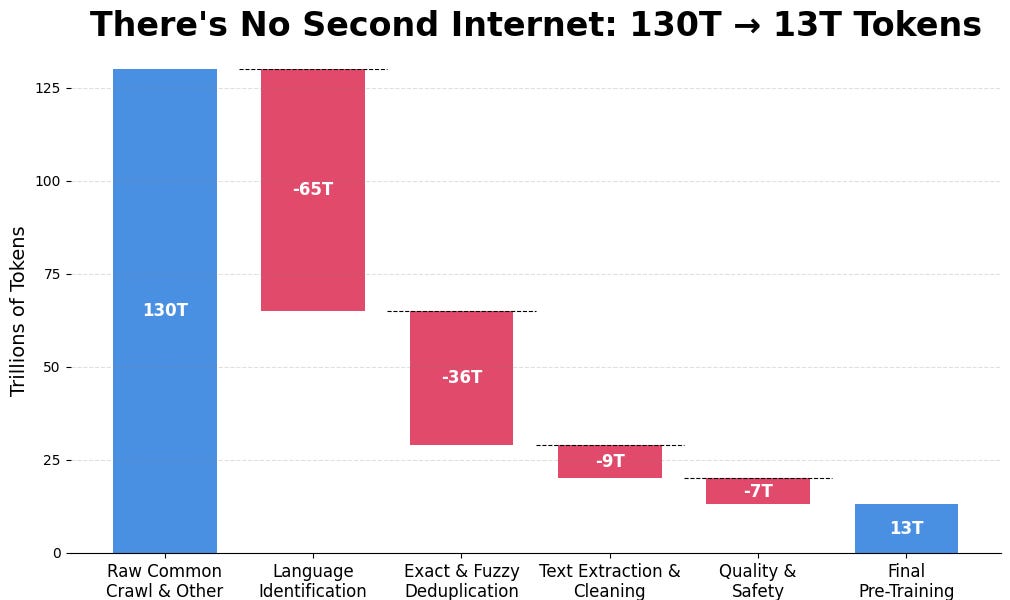
本文是三篇关于大型语言模型 (LLM) 工作原理的“现状”文章中的第二篇,目标读者是像2022年中期的我一样,对AI没有深入了解的科技爱好者。文章延续了作者学习Sebastian Raschka的《从零构建大型语言模型》系列的第19部分,解释了LLM中向量、矩阵以及高维空间(词汇空间和嵌入空间)的运用。作者指出,理解LLM的推理过程只需要高中水平的数学知识,而训练过程则需要更复杂的数学。文章详细解释了向量在高维空间中的表示,以及矩阵乘法如何实现不同高维空间之间的投影,并将其与神经网络中的线性层联系起来。
AI